
With the extensive usage of cloud-based technologies to perform machine learning and data science related experiments, choosing the right toolset/ platform to perform the operations is a key part for the project success.
Since selecting the perfect toolset for our ML workloads maybe bit tricky, I thought of sharing my thoughts on that by getting a couple of generic use cases. Please keep in mind that the use cases I have chosen and the decisions I’m suggesting are totally my own view on the scenarios and this may differ based on different factors (amount of data, time frame, allocated budget, ability of the developer etc.) you have with your project. Plus, the suggestions I’m pointing out here are from the services comes with Microsoft Azure cloud. This maybe the easily adjusted for other cloud providers too.
Scenario 1:
We are a medium scale micro financing company having our data stored on Microsoft Azure. We have a plan to build a datalake and use that for analytical and reporting tasks. We have a diverse data team with abilities in python, Scala and SQL (most of the data engineers are only familiar with SQL). We need to build a couple of machine learning models for predictions. What would be the best platform to go forward with? Azure Databricks or Azure ML Studio?
Suggestion: Azure Databricks
Reasons:
- Databricks is more flexible in ETL and datalake related data operations comparing to AzureML Studio.
- You can perform data curation and machine learning within a single product with Azure Databricks.
- Databricks can connect with Azure Data Factory pipelines to handle data flow and data curation tasks within the datalake.
- Since the data engineers are more familiar with SQL, they’ll easily adapt with SparkSQL on Databricks.
- Data team can develop their machine learning experiments with any language of their choice with Databricks notebooks.
- Databricks notebooks can be used for analytical and reporting tasks even with a combination of PowerBI.
- Given that, the company is planning for building a datalake, Databricks is far more flexible in ETL tasks. You can use Azure Data Factory pipelines with Databricks to control the data flow of the datalake.
Scenario 2:
I’m a computer science undergrad. I’m doing a software project to predict several types of wildflowers by capturing images from a mobile phone. I’m planning to build my computer vision model using TensorFlow and Keras and expose the service as a REST API. Since I’m not having the infrastructure to train the ML models, I’m planning to use Azure for that. Which tool on Azure should I choose?
Suggestion: Azure ML Studio
Reasons:
- AzureML provides a complete toolset to train, test and deploy a deep learning model using any open-source framework of your choice.
- You can use the GPU training clusters on AzureML to train your models.
- It’s easy to log your model training and experiments using AzureML python SDK.
- AzureML gives you the ability for model management and exposing the trained model as a REST API.
- Small learning curve and adaptability.
Scenario 3:
I’m the CEO of a retail company. I’m not having a vast experience with computing or programming but having a background in maths and statistics. I have a plan to use machine learning to perform predictive analysis with the data currently having in my company. Most of the data are still in excel! Someone suggested me to use Azure. What product on Azure should I choose?
Suggestion: Azure ML Studio
Reasons:
- For a beginner in machine learning and data science, Azure ML Studio is a good start.
- AzureML Studio provides no-code environments (Azure ML designer and AutoML) to develop ML models.
- Since, you are mostly in the experimental stage and not going for using bigger datasets, using Databricks would be an overkill.
- You can easily import your prevailing data and start experimenting and playing around with them without any local environmental setup.
Scenario 4:
I’m the IT manager of a large enterprise who are heavily relying on data assets with our decision-making process. We have to run iterative jobs daily to retrieve data from different external sources and internal systems. Currently we have an on-prem SQL database acting as the data warehouse. Company has decided to go for cloud. Can Azure serve our needs?
Suggestion: Yes. Azure can serve your need with different tools in the data & AI domain.
Reasons:
- You can use Azure Synapse Analytics or Azure Data Factory to build data pipelines and perform ETL operations.
- The local data warehouse can be easily migrated to Azure cloud.
- You can use Azure Databricks in-order to perform analytics tasks.
- Since the enterprise in large and scaling, using Databricks would be better with its Spark based computation abilities.
Scenario 5:
We are an agricultural company growing forward with adopting modern Agri-tech into the business. We collect numerous data values from our plantations and store them in our cloud databases. We have a set of data scientists working on data modelling and building predictive models related to crop fertilizing and harvesting. They are currently using their own laptops to perform analysis and it’s troublesome with the data amount, platform configurations and security. Will Azure ML comes handy in our case?
Suggestion: Yes. Azure ML Studio would be a good choice.
Reasons:
- AzureML can be easily adaptable as an analytical platform.
- The cloud databases can be connected to AzureML, and data scientists can straight-up start working on the data assets.
- AzureML is relatively cheap comparing to Databricks (Given the data amount is manageable in a single computer.)
- It’s easy to perform prototyping of models using AutoML/ AzureML Designer and then implement the models within a short time frame.
Generally, these are the factors I would keep in mind when selecting the services for ML/ data related implementations on Azure.
- Azure ML studio is good when you are training with a limited data, though Azure ML provides training clusters, the data distribution among the nodes is to be handled in the code.
- AzureML Studio comes handy in prototyping with AzureML designer and Automated ML.
- Azure Databricks with its RDDs is designed to handle data distributed on multiple nodes which is advantageous when your you have big datasets.
- When your data size is small and can fit in a scaled up single machine/ you are using a pandas dataframe, then use of Azure Databricks is an overkill.
- Services like Azure Data Factory and Datalake storage can be easily interconnected for building
Let me know your thoughts on these scenarios as well. Add your queries in the comments too. I’ll try my best to provide my suggestions for those use cases.

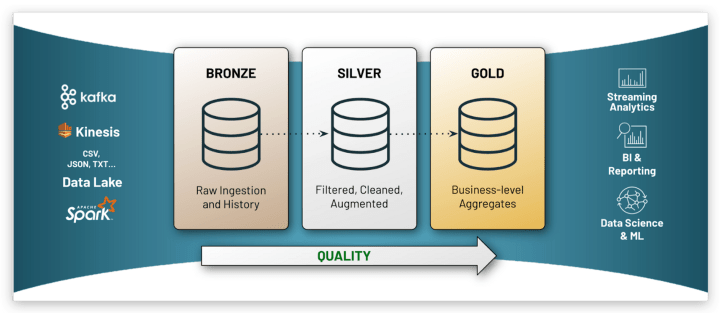










 When it comes to a machine learning or data science related problem, the most difficult part would be finding out the best approach to cope up with the task. Simply to get the idea of where to start!
When it comes to a machine learning or data science related problem, the most difficult part would be finding out the best approach to cope up with the task. Simply to get the idea of where to start!
 We have already passed the era of gigabytes when it comes to data. World is talking about terabytes of unstructured data and massive amounts of data points generated from IoT devices and sensors in millions per a second. To analyze these heaps of data, obviously, we need large computation power and massive storage. Building workhorse machines to fulfil those tremendous workloads would definitely cost a lot. Cloud computing paradigm comes handy here. The resourcefulness and the scalability of the public cloud can be used to perform the large calculations in machine learning algorithms.
We have already passed the era of gigabytes when it comes to data. World is talking about terabytes of unstructured data and massive amounts of data points generated from IoT devices and sensors in millions per a second. To analyze these heaps of data, obviously, we need large computation power and massive storage. Building workhorse machines to fulfil those tremendous workloads would definitely cost a lot. Cloud computing paradigm comes handy here. The resourcefulness and the scalability of the public cloud can be used to perform the large calculations in machine learning algorithms.
 My personal favorite here is the Linux DSVM instance. Here I’ve created a Linux DSVM with the basic configurations. For accessing the VM you can use any tool that can do a SSH call. What I normally do is calling the accessing the VM using Ubuntu Bash on Windows 10.
My personal favorite here is the Linux DSVM instance. Here I’ve created a Linux DSVM with the basic configurations. For accessing the VM you can use any tool that can do a SSH call. What I normally do is calling the accessing the VM using Ubuntu Bash on Windows 10.



 Here’s my Azure VM specifically configured for deep learning exercises. The machine is powered with Tesla K80 GPU which is having 4992 cores in it!! I installed anaconda for that and doing computations using Jupyter notebooks.
Here’s my Azure VM specifically configured for deep learning exercises. The machine is powered with Tesla K80 GPU which is having 4992 cores in it!! I installed anaconda for that and doing computations using Jupyter notebooks.





