A Large Language Model as a Van Gogh Artwork (Dall-E2)
The hype on Generative AI is still there. Everyone is looking for applications of GenAI and investing to get a competitive advantage for businesses with AI-based interventions. These are a couple of questions I came across, as well as my view on LLMs and their future.
Can we achieve everything with LLMs now?
The straightforward answer is NO! LLMs can’t handle all tasks and are best suited as tools for most natural language processing tasks, particularly in information retrieval and conversational applications. Despite their strengths, there are still plenty of simple approaches that find practical use in real-world scenarios. In simpler terms, LLMs have their unique use cases, but they can’t do everything like a wizard!
Are LLMs taking over the tech world?
Is this the end of traditional ML? Not at all. As mentioned earlier, LLMs don’t cover all machine learning tasks. Most data analytical and machine learning use cases involve numerical data often organized in a relational structure, where traditional machine learning algorithms excel. Traditional machine learning techniques are expected to remain relevant for the foreseeable future.
Artificial General Intelligence (AGI)?
Have we reached it? General Artificial Intelligence (General AI) envisions AI systems with human-like abilities across various tasks. However, we are not there yet. While there’s a possibility of achieving some level of AGI, current LLMs, including applications like ChatGPT, should not be confused with AGIs. LLMs are proficient in predicting text frequencies using transformers but struggle with complex analytical tasks where human expertise is crucial.
Are enterprises ready for the AI hype?
Having worked with numerous enterprises, I’ve observed a willingness to invest in AI projects for streamlining business processes. However, many struggle to identify suitable use cases with a considerable Return on Investment (RoI). Some organizations, even if prepared for advanced analytics, face extensive groundwork in their IT and data infrastructure. Despite these challenges, the AI hype has prompted businesses to recognize the potential of leveraging organizational data resources effectively. In the coming months, we anticipate a significant boost not only in LLM-based applications but also in traditional machine learning and deep learning applications across industries.
Ethical AI? What’s happening there?
With the public’s increasing adoption of ChatGPT and large language models, conversations about responsible AI use have gained traction. The European Union has passed pioneering AI legislation, and Australia is actively working on regulating AI systems and establishing ethical AI guidelines. Countries like Australia have introduced AI ethics frameworks and established National AI Centres to promote responsible AI practices and innovation.
Leading companies like Microsoft are contributing to responsible AI by introducing guidelines and toolboxes for transparent machine learning application development. Governments and corporations are moving towards regulating and controlling AI applications, a positive development in ensuring responsible AI use.
There’s no turning back now. We must all adapt to the next wave of AI and prepare to harness its full potential.
Since the launch of ChatGPT in last November, not only the tech community, but also the general public started peeping into the world of AI. As mentioned in my article “AI summer is Here”, organisations are looking for avenues where they can use the power of AI and advance analytics to empower their business processes and gain competitive advantage.
Though everyone is looking forward for using AI, are we really ready? Are we there?
These are my thoughts on the pathway an organisation may follow to adopt AI in their business processes with a sensible return on investment.
First of all, there’s a key concept we should keep in mind. “AI is not a wizard or a magical thing that can do everything.” It’s a man-made concept build upon mathematics, statistics and computer science which we can use as a toolset for certain tasks.
We want to use AI! We want to do something with it! OR We want to do everything with it!
Hold on… Though there’s a ‘trend’ for AI, you should not jump at it without knowing nothing or without analysing your business use cases thoroughly. you should first identify what value the organization is going to gain after using AI or any advance analytics capability. Most likely you can’t do everything with AI (yet). It’s all about identifying the correct use case and correct approach that aligns with your business process.
Let’s not focus on doing something with AI. Let’s focus on doing the right thing with it.
We have a lot of data! So, we are there, right?
Data is the key asset we have when it comes to any analytical use case. Most of the organizations are collecting data with their processes from day 1. The problem lies with the way data is managed and how they maintain data assets and the platform. Some may have a proper data warehouse or lake house architecture which has been properly managed with CI/CD concepts etc, but some may have spread sheets sitting on a local computer which they called their “data”!
The very first thing an organization should do before moving into advance analytics would be streamlining their data platform. Implementing a proper data warehouse architecture or a data lake architecture which follows something similar to Medallion architecture would be essential before moving into any analytics workloads.
If the organization is growing and having a plan to use machine learning and data science within a broader perspective, it is strongly recommended to enable MLOps capabilities within the organization. It would provide a clear platform for model development, maintenance and monitoring.
Having a lot of data doesn’t mean you are right on track. Clearing out the path and streamlining the data management process is essential.
Do we really need to use AI or advance analytics?
This question is real! I have seen many cases where people tend to invest on advance analytics even before getting their business processes align with modern infrastructure needs. It’s not something that you can just enable by a click of a button. Before investing your time and money for AI, first make sure your IT infrastructure, data platforms, work force and IT processes are up to date and ready to expand for future needs.
For an example, will say you are running a retail business which you are planning to use machine learning to perform sales forecasts. If your daily sales data is still sitting on a local SQL server and that’s the same infrastructure you going to use for predictive analytics, definitely that’s going to be a failure. First make sure your data is secured (maybe on a cloud infrastructure) and ready to expose for an analytical platform without hassling with the daily business operations.
ChatGPT can do everything right?
ChatGPT can chat! 😀
As I stated previously, AI is not a wizard. So as ChatGPT. You can use ChatGPT and it’s underlying OpenAI models mostly for natural language processing based tasks and code generation and understanding (Keep in mind that it’s not going to be 100% accurate). If your use case is related to NLP, then GPT-3 models may be an option.
When to use generative AI?
Variational Autoencoders, Generative Adversarial Networks and many more have risen and continue to advance the field of AI. That has given a huge boost for the domain of generative AI. These models are capable of generating new examples that are like examples from a given dataset.
It is being used in diverse fields such as natural language processing (GPT-3, GPT-4), computer vision (DALL-E), speech recognition and many more.
OpenAI is the leading Generative AI service provider in the domain right now and Microsoft Azure offers Azure OpenAI, which is an enterprise level serving of OpenAI services with additional advantages like security and governance from Azure cloud.
If you are thinking about using generative AI with your business use case, strongly recommend going through the following considerations.
If you have said yes to all of the above, then OpenAI may be the right cognitive service to go with.
If it’s not the case, you have to look at other machine learning paradigms and off-the-shelf ML models like cognitive services which may cater better to the scenario.
Ok! What should be the first step?
Take a deep dive for your business processes and identify the gaps in digital transformation. After addressing those ground level issues, then look on the data landscape and analyse the possibilities of performing analytical tasks with the it. Start with a small non-critical use case and then move for the complex scenarios.
If you have any specific use cases in mind, and want to see how AI/ machine learning can help to optimize those processes, I’m more than happy to have a discussion with you.
btw, the image on the top is generated by DALL-E with the prompt of “A cute image of a robot toy sitting near a lake – digital art“
Undoubtedly, we are going through another AI summer where we see a rapid growth in Artificial Intelligence based interventions. Everyone is so keen on using applications like ChatGPT and want to know what’s the next big thing. On my last post, I was discussing the underlying technicalities of large language models (LLMs) which is the baseline of ChatGPT.
Through this post, I’m trying to give my opinion on some of the questions raised by my colleagues and peers recently. These are my own opinions and definitely there can be different interpretations.
What’s happening with AI right now?
Yes. AI is having a good time! 😀 Recently almost all the mainstream media started talking about AI and it’s good and bad. Even people who are not very interested in technology started their research on AI. In my point of view, it all happened since major tech companies and research institutes came out with AI base products that general public can use not only for business operations, but also for entertainment purposes. For example, AI base image generation tools (mostly based on artificial neural models as Dall-E) started getting popular in social media. ANN based image filters and chatting applications conquered all around social media.
All these fun stuffs didn’t come overnight. Those products have been under research and development for years. There have been more interesting stuff happening in research world and the problem was giving an easy accessibility of their abilities for general public.
Right now, we can see a clear motivation from enterprises to make AI more accessible and user-friendly. The barrier of having extensive understanding on mathematics and related theories to use AI and machine learning is getting reduced day by day.
Yes. I see that as a good trend.
ChatGPT is the only big thing happened right?
No, it’s not! ChatGPT is an application build upon the capabilities of GPT-3 which is a LLM. OpenAI has announced they are coming up with GPT-4 soon, which is going to be much more powerful in understanding human language and images.
With the large computation capabilities opening up with technological advancements like cloud, we can observe research is going towards training massive neural networks to understand the non-linear data such as natural language, image and videos. The recent advancements of architectures like Transformers (which was introduced in 2017), has making very big changes in computer vision too.
Applications such as GitHub Copilot, an AI pair programming application gives software developers the ability to code faster and produce more reliable outcome efficiently.
Microsoft announced, Copilot is going to be a part of their office365 suite, which is widely used in many industries. It’s going to be a definite big change for the way that people work with computers today.
I’m a tech folk. How AI is going to affect my career?
I work in the AI domain. The advancement of AI directly affects my career and I always keep myself busy reading and grabbing new trends as much as I could (which is impossible with this rate!)
AI developers or the machine learning engineers are not the only groups getting affected directly with these advancements. Remember how cloud technologies changed the way we operate in enterprises, completely eliminating the excessive usage of cumbersome networking devices and in-house servers. I feel something similar is going to happen with AI too. IT folks may have to adapt for using AI As a Service in application development life cycle. You can be a dinosaur. Let’s get updated!
I’m a non-tech person. How AI is going to affect me?
It’s not only for tech savvy folks. Since, the trend is all about making AI more accessible, the AI based interventions are going to be there in almost all the industries. Starting from retail business, the knowledge focused industries such as legal and education going too going to get affected with the ways of working.
If you are a non-tech person definitely you should research on the ways of using AI and machine learning in your career.
Can AI displace people from job?
Yes and no! According to a McKinsey study, Artificial intelligence could displace roughly 15% of workers, or 400 million people, worldwide between 2016 and 2030! Most the monotonous jobs will get replaced with robots and AI applications. For example, the manual labour needed for heavy lifting in factories will be replaced with computer vision assisted robots. Some monotonous tasks in domains like accounting will be replaced by automated applications powered with AI based applications.
In the meanwhile, new job will be generated to assist AI powered operations. The term data scientist was not widely used even a decade ago. Now it has become one of the most demanding professions. It’s just an example.
Isn’t excessive use of AI is harmful?
Excessive use of anything is harmful! It’s the same with AI too. There are many discussions going on related to regulating human-competitive machine intelligence. Enterprises are working towards concepts such as responsible AI to make sure AI systems are not harmful for the betterment of mankind and the nature.
To be frank, one can argue that AI base systems are reducing the critical thinking ability and the creative power of humans. In a way that can be true in some contexts. We should find ways to keep it as only a tool, but not totally rely on it.
Recently, an open letter titled “Pause Giant AI Experiments” was published enforcing the need of proper rule sets and legislations around AI systems. It was signed by profound scientists including Yoshua Bengio and known tech folks as Elon Musk.
Personally, I strongly believe a framework on regulating the usage of AI interventions should be there and the knowhow on such applications should be made widely available for general public.
That’s not something can be done overnight. Global organisations and governments should start working together soon as possible to make it happen.
What’s the future would look like with AI?
It’s something we actually can’t predict. There will be more AI applications which may have human-like abilities and even more than that in some domains. The way people work will change drastically with the wide accessibility of AI. As we use electricity today to make our lives easy, the well-managed AI systems will be assisting us with our daily chaos. Definitely we may have to keep our eyes open!
Docker has revolutionized the way applications are developed and deployed by making it easier to build, package, and distribute applications as self-contained units that can run consistently across different environments.
I’ve been using docker as a primary tool with my machine learning experiments for a while. If you interested in reading how sweet the docker + machine learning combo is; you can hop to my previous blog post here.
Docker is important in machine learning for several reasons:
Reproducibility: In machine learning, reproducibility is important to ensure that the results obtained in one environment can be replicated in another environment. Docker makes it easy to create a consistent, reproducible environment by packaging all the necessary software and dependencies in a container. This ensures that the code and dependencies used in development, testing, and deployment are the same, which reduces the chances of errors and improves the reliability of the model.
Portability: Docker containers are lightweight and can be easily moved between different environments, such as between a developer’s laptop and a production server. This makes it easier to deploy machine learning models in production, without worrying about differences in the underlying infrastructure.
Scalability: Docker containers can be easily scaled up or down to handle changes in the demand for machine learning services. This allows machine learning applications to handle large amounts of data and processing requirements without requiring a lot of infrastructure.
Collaboration: Docker makes it easy to share machine learning models and code with other researchers and developers. Docker images can be easily shared and used by others, which promotes collaboration and reduces the amount of time needed to set up a new development environment.
Overall, Docker simplifies the process of building, deploying, and managing machine learning applications, making it an important tool for data scientists and machine learning engineers.
Alright… Docker is important. How can we get started?
I’ll share the procedure I normally follow with my ML experiments. Then demonstrate the way we can containerize a simple ML experiment using docker. You can use that as a template for your ML workloads with some tweaks accordingly.
I use python as my main programming language and for deep learning experiments, I use PyTorch deep learning framework. So that’s a lot of work with CUDA which I need to work a lot with configuring the correct environment for model development and training.
Since most of us use anaconda as the dev framework, you may have the experience with managing different virtual environments for different experiments with different package versions. Yes. That’s one option, but it is not that easy when we are dealing with GPUs and different hardware configurations.
In order to make my life easy with ML experiments, I always use docker and containerize my experiments. It’s clean and leave no unwanted platform conflicts on my development rig and even on my training cluster.
Yes! I use Ubuntu as my OS. I’m pretty sure you can do this on your Mac and also in the Windows PC (with bit of workarounds I guess)
All you need to get started is installing docker runtime in your workstation. Then start containerizing!
Here’s the steps I do follow:
I always try to use the latest (but stable) package versions in my experiments.
After making sure I know all the packages I’m going to use within the experiment, I start listing down those in the environment.yml file. (I use mamba as the package manager – which is similar to conda but bit faster than that)
Keep all the package listing on the environment.yml file (this makes it lot easier to manage)
Keep my data sources on the local (including those in the docker image itself makes it bulky and hard to manage)
Configure my experiments to write its logs/ results to a local directory (In the shared template, that’s the results directory)
Mount the data and results to the docker image. (it allows me to access the results and data even after killing the image)
Use a bash script to build and run the docker container with the required arguments. (In my case I like to keep it as a .sh file in the experiment directory itself)
In the example I’ve shared here, a simple MNIST classification experiment has been containerized and run on a GPU based environment.
I used a ubuntu 20.04 base image from nvidia with CUDA 11.1 runtime. The package manager used here is mamba with python 3.8.
FROM nvidia/cuda:11.1.1-base-ubuntu20.04
# Remove any third-party apt sources to avoid issues with expiring keys.
RUN rm -f /etc/apt/sources.list.d/*.list
# Setup timezone (for tzdata dependency install)
ENV TZ=Australia/Melbourne
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime
# Install some basic utilities and dependencies.
RUN apt-get update && apt-get install -y \
curl \
ca-certificates \
sudo \
git \
bzip2 \
libx11-6 \
libgl1 libsm6 libxext6 libglib2.0-0 \
&& rm -rf /var/lib/apt/lists/*
# Create a working directory.
RUN mkdir /app
WORKDIR /app
# Create a non-root user and switch to it.
RUN adduser --disabled-password --gecos '' --shell /bin/bash user \
&& chown -R user:user /app
RUN echo "user ALL=(ALL) NOPASSWD:ALL" > /etc/sudoers.d/90-user
USER user
# All users can use /home/user as their home directory.
ENV HOME=/home/user
RUN chmod 777 /home/user
# Create data directory
RUN sudo mkdir /app/data && sudo chown user:user /app/data
# Create results directory
RUN sudo mkdir /app/results && sudo chown user:user /app/results
# Install Mambaforge and Python 3.8.
ENV CONDA_AUTO_UPDATE_CONDA=false
ENV PATH=/home/user/mambaforge/bin:$PATH
RUN curl -sLo ~/mambaforge.sh https://github.com/conda-forge/miniforge/releases/download/4.9.2-7/Mambaforge-4.9.2-7-Linux-x86_64.sh \
&& chmod +x ~/mambaforge.sh \
&& ~/mambaforge.sh -b -p ~/mambaforge \
&& rm ~/mambaforge.sh \
&& mamba clean -ya
# Install project requirements.
COPY --chown=user:user environment.yml /app/environment.yml
RUN mamba env update -n base -f environment.yml \
&& mamba clean -ya
# Copy source code into the image
COPY --chown=user:user . /app
# Set the default command to python3.
CMD ["python3"]
In the beginning you may see this as an extra burden. Trust me, when your experiments get complex and you start working with different ML projects parallelly, docker is the lifesaver you have and it’s going to save you a lot of unnecessary time you waste on ground level configurations.
Data is the key component of machine learning. Thus, high quality training dataset is always the main success factor of a machine learning training process. A good enough dataset leads to more accurate model training, faster convergence as well as it’s the main deciding factor on model’s fairness and unbiases too. Let’s discuss the dos and don’ts when selecting/ preparing a dataset for training a machine learning model and the factors we should consider when composing the training data. These are valid for structured numerical data as well as for unstructured data types such as images and videos.
What does the dataset’s distribution look like?
This is important mostly with numerical datasets. Calculating and plotting the frequency distribution (how often each value occurs in the dataset) of a dataset leads us to the insights on the problem formation as well as on class distribution. ML engineers tend to have datasets with normal distribution to make sure they are having sufficient data points to train the models.
Though normal distribution is more common in nature and psychology, there’s no need of having a normal distribution on every dataset you use for model training. (Obviously some real-world data collections don’t fit for the noble bell curve).
Does the dataset represent the real world?
We are training machine learning models to solve real world problems. So, the data should be real too. It’s ok to use synthetic data if you are having no other option to collect more data or need to balance the classes, but always make sure to use the real -world data since it makes the model more robust on testing/ production. Please don’t put some random numbers into a machine learning model and expect that to solve your business problem with 90% accuracy 😉
Does the dataset match the context?
Always we must make sure the characteristics of the dataset used for training the model matches with the conditions we have when the model goes live in production. For example, will say we need to train a computer vision model for a mobile application which identify certain types of tree leaves from images captured from the mobile camera. There’s no use of training the model with images only captured in a lab environment. You should have images which are captured in wild (which is closely similar for the real-world use case of the application) in your training set.
Is the data redundant?
Data redundancy or data duplication is important point to pay attention when training ML models. If the dataset contains the same set of data points repeatedly, model overfits for that data points and will not perform well in testing. (mostly underfitting)
Is the dataset biased?
A bias dataset never produces an unbiased trained model. Always the dataset we choose should be balanced and not bias to certain cases. Let’s get an example of having a supervised computer vision model which identifies the gender of people based on their face. Will assume the model is trained only with images from people from USA and we going to use it in an application which is used world-wide. The model will produce unrealistic predictions since the training context is bias to a certain ethnicity. To get a better outcome, the training set should have images from people from different ethnicities as well as from different age groups.
Which data is there too little/too much of?
“How much data we need to train a model with good accuracy?” – This is a question which comes out quite often when we planning ML projects. The simple answer is – “we don’t know!” 😀 There are no exact numbers on how much of data needed for training a ML model. We know that deep learning models are data hungry. Yes, we need to have large datasets for training deep neural networks since we are using those for representing non-linear complex relationships. Even with traditional machine learning algorithms, we should make sure to have enough data from all the classes even from the edge/ corner cases. What will happen if we have too much data? – that doesn’t help at all. It only makes the training process lengthy and costly without getting the model into a good accuracy. This may end up producing an overfitted trained model too.
These are only very few points to consider when selecting a dataset for training a machine learning model. Please add your thoughts on dataset selection in comments.
We have discussed a lot about Azure Machine Learning Studio; the one-stop portal for all ML related workloads on Azure cloud. AzureML Studio provides different approaches to work on the machine learning experiments based on needs, resources and constraints you have. Selecting the plan to attack is completely your choice.
We all have our own way of performing machine learning experiments. While some prefer working on Jupyter notebooks, some are more into less code environments. Being able to onboard data scientists with their familiar development environment without a big learning overhead is one of the main advantages of AzureML.
In this article, let’s have a discussion on different methods available in AzureML studio and their usage in practical scenarios. We may discuss pros and cons of each approach as well.
Please keep in mind that, these are my personal thoughts based on the experiences I had with ML experiments and this may change in different scenarios.
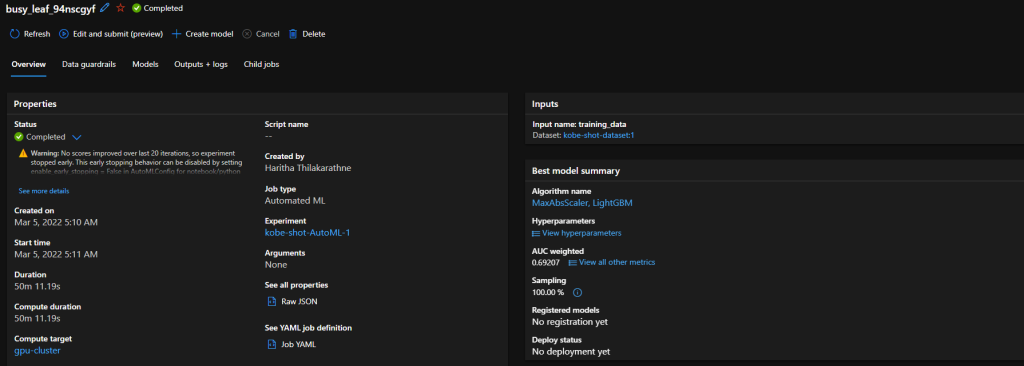
Automated ML
Summary of an Automated ML experiment
As the name implies, this is all automated. Automated ML is the easiest way of producing a predictive model just in few minutes. You don’t need to have any coding experience to use Automated ML. Just need to have an idea on machine learning basics and an understanding on the problem you going to solve with ML.
The process is pretty straight forward. You can start with selecting the dataset you want to use for ML model training and specify the ML task you want to perform. (Right now, it supports classification, regression, time series forecasting. Computer vision and NLP tasks are in preview). Then you can specify the algorithms you want to test it with and other optional parameters. Azure does all the hard work for you and provides a deployment ready model which can be exposed as a REST API.
Pros:
Zero code process.
Easy to use and well suited for fast prototyping.
Eliminate the environment setup step in ML model development
Limited knowledge on machine learning is needed to get a production viable result.
Cons:
Limited machine learning capabilities.
Right now, only works with supervised learning problem scenarios.
Works well with relational data, computer vision and NLP are still in preview.
There’s no way of using custom machine learning algorithms in the process.
Azure ML Designer
Azure ML Designer
Azure ML Designer is an upgraded version of the pretty old Azure ML Studio drag and drop version. Azure ML Designer is having a similar drag and drop interface for building machine leaning experiment pipelines. You have a set of prebuilt components which you can connect together in a flowchart like manner to build machine learning experiments. You have the ability to use SQL queries or python/ R scripts if you want in the process too. After training a viable ML model, you can deploy it as a web service with just few clicks.
I personally prefer this for prototyping. Plus, I see a lot f potential on Azure ML designer in educational purposes. It’s really easy to visualize the ML process through the designer pipelines and it increases the interpretability of the operation.
Pros:
Zero code/ Less code environment
Easy to use graphical interface
No need to worry on development/ training environment configurations
Having the ability to expand the capabilities with python/ R scripts
Easy model deployment
Cons:
Less flexibility for complex ML model development.
Less support for deep learning workloads.
Code versioning should handle separately.
Azure ML notebooks
Performing data visualization on AzureML notebooks
This maybe the most favourite feature on Azure ML for data scientists. I know Jupyter notebooks are like bread and butter for data scientists. Azure ML offers a fully managed notebook experience for them without giving them the hassle of setting up the dev environment on local computers. You just have to connect the notebook with a compute instance and it allows you to do your model development and training on cloud in the same way you did on a local compute or elsewhere on notebooks.
I would recommend this as the to-go option for most of the machine learning experiments since it’s really easy to spin up a notebook instance and get the job done. Most of the ML related libraries are pre-installed on the compute instance and you even have the flexibility to install 3rd party packaged you need through conda or pip.
Pros:
Familiar notebook experience on cloud.
Option to use different python kernels.
No need to worry about dev environment setup on local compute.
Can use the powerful compute resources on Azure for model training.
Flexibility to install required libraries through package managers.
Cons:
Comes with a price for computation.
No direct support for spark workloads.
Code version control should manage separately.
Developing on local and connect to AzureML service through AML Python SDK.
This is the option I would suggest for more advanced users. Think of a scenario where you have a deep learning based computer vision experiment to run on Azure with a complex code base. If this is the case, I would definitely use AzureML python SDK and connect my prevailing code base with the AzureML service.
In this approach, your code base sits on your local computer and you are using Azure for model training, deployment and monitoring purposes. You have the total flexibility of using the power of cloud for computations as well as the flexibility of using local machine for development.
Pros:
Total flexibility in performing machine learning experiments with our comfortable dev tools.
AzureML python SDK is an open-source library.
Code version controlling can be handled easily.
Whole ML process can be managed using scripts. (Easy for automation)
Cons:
Setting up the local development environment may take some effort.
Some features are still in experimental stage.
Choosing the most convenient approach for your ML experiment is totally based on the need and resources you have. Before getting into the big picture, start small. Start with a prototype, then a workable MVP, gradually you can move forward with expanding it with complex machine learning approaches.
What’s your most preferred way of model development from these options? Please mention in the comments.
What’s all this hype on MLOps? What’s the difference between machine learning and MLOps? Is MLOps essential? Why we need MLOps? Through this article series we going to start a discussion on MLOps to get a good start with the upcoming trend. The first post is not going to go deep with technicalities, but going to cover up essential concepts behind MLOps.
What is MLOps?
As the name implies, it is obviously having some connection with DevOps. So, will see what DevOps is first.
“A compound of development (Dev) and operations (Ops), DevOps is the union of people, process, and technology to continually provide value to customers.”
Microsoft Docs
This is the formal definition of DevOps. In the simpler terms, DevOps is the approach of streamlining application development life cycle of software development process. It ensures the quality engineering and security of the product while making sure the team collaboration and coordination is managed effectively.
Imagine you are a junior level developer in a software development company who develops a mission critical system for a surveillance application. DevOps process make sure each and every code line you write is tracked, managed and integrated to the final product reliably. It doesn’t stop just by managing the code base. It involves managing all development life cycle steps including the final deployment and monitoring of the final product iteratively too.
That’s DevOps. Machine Learning Operations (MLOps) is influenced by DevOps principles and practices to increase the efficiency of machine learning workflows. Simply, it’s the way of managing ML workflows in a streamlines way to ensure quality, reliability, and interpretability of machine learning experiments.
Is MLOps essential?
We have been playing around with machine learning experiments with different tools, frameworks and techniques for a while. To be honest, most of our experiments didn’t end up in production environments :D. But, that’s the ultimate goal of predictive modeling.
Building a machine learning model and deploying it is not a single step process. It starts with data collection and goes in an iterative life cycle till monitoring the deployed model in the production environment. MLOps approaches and concepts streamline these steps and interconnect them together.
Answer is Yes! We definitely need MLOps!
Why we need MLOps?
As I said earlier, MLOps interconnect the steps in ML life cycle and streamline the process.
I grabbed these points from Microsoft docs. As it implies, these are the goals of MLOps.
Faster experimentation and development of models
Good MLOps practices leads for more code and component reusability which leads for faster experiments and model development. For an example, without having separate training loops or data loading components for each experiment, we can reuse an abstract set of methods for those tasks and connect them with a machine learning pipeline for running different experiment configurations. That’s make the life easy of the developer a lot!
I do lot of experiments with computer vision. In my case, I usually have a set of abstract python methods that can be used for model training and model evaluation. When performing different experiments, I pass the required parameters to the pipeline and reuse the methods which makes the life easy with less coding hassle.
Faster deployment of models into production
Machine learning model deployment is always a tricky part. Managing the endpoints and making sure the deployment environment is having all the required platform dependencies maybe hard to keep track with manual processes. A streamlines MLOps pipeline helps to manage deployments by enabling us to choose which trained model should go for production etc. by keeping track of a model registry and deployment slots.
Quality assurance and end-to-end lineage tracking
Maintaining good coding practices, version controlling, dataset versioning etc. ensures the quality of your experiments. Good MLOps practices helps you to find out the points where errors are occurring easily rather than breaking down the whole process. Will say your trained model is not performing well with the testing data after sometime from model deployment. That might be caused by data drift happened with time. Correctly configured MLOps pipeline can track such changes in the inference data periodically and make sure to notify such incidents.
Trustworthiness and ethical AI
This is one of the most important use cases of MLOps. It’s crucial to have transparency in machine learning experiments. The developer/ data scientist should be able to interpret each and every decision they took while performing the experiment. Since handling data is the key component of ML model, there should be ways to maintain correct security measures in experiments too. MLOps pipelines ensure these ethical AI principles are met by streamlining the process with a defined set of procedures.
How we gonna do this?
Now we all know MLOps is crucial. Not just having set of python scripts sitting in a notebook it’s all about interconnecting all the steps in a machine learning experiments together in an iterative process pipeline. There are many methods and approaches to go forward with. Some sits on-prem while most of the solutions are having hybrid approach with the cloud. I usually use lot of Azure services in my experiments and Azure machine learning Studio provides a one-stop workbench to handle all these MLOps workloads which comes pretty handy. Let’s start with a real-world scenario and see how we can use Azure Machine Learning Studio in MLOps process to streamline our machine learning experiments.
It’s almost 7 years since I started playing with machine learning and related domains. These are some FAQs that comes for me from peers. Just added my thoughts on those. Feel free to any questions or concerns you have on the domain. I’ll try my best to add my thoughts on that. Note that all these answers are my personal opinions and experiences.
01. How to learn the theories behind machine learning?
The first thing I’d suggest would be ‘self-learning’. There are plenty of online resources out there where you can start studying by your own. Most of them are free. Some may need a payment for the certification (That’s totally up to you to pay and get it). I’ve listed down some of the famous places to get a kickstart for learning AI. Just take a look here.
Next would be keep practising. Never stop coding and training models in various domains. Kaggle is a good place to sharpen your skill set. Keep learning and keep practising at the same time.
02. Do we really need mathematics for ML?
Yes. To some extend you should know the theories behind probability and and some from basic mathematics. No need to worry a lot on that. As I said previously, there are plenty of places to catch up your maths too.
03. Is there a difference between data analysis and machine learning?
Yes. There is. Data analysis is about find pattern in the prevailing data and obtain inferences due to those patterns. It may have the data visualization components too. When is comes to machine learning, you train a system to learn those patterns and try to predict the upcoming pattern.
04. Does the trend in AI/ML going to fade out in the near future?
Mmm.. I don’t think so. Can’t exactly say AI is going to be ‘the’ future. Since all these technical advancements going to generate hell a lot of data, there should be a way to understand the patterns of those data and get a value out of that. So, data science and machine learning is going to be the approach to go for.
Right… those are some general questions I frequently get from people. Let’s move into some technicalities.
05. What’s the OS you use on your work rig?
Ubuntu! Yes it’s FOSS and super easy to setup all the dependencies which I need on it. (I did a complete walk through on my setup previously. Here’s it). Sometimes I use Windows too. But if it’s with docker and all, yes.. Ubuntu is the choice I’m going with.
06. What’s your preferred programming language to perform machine learning experiments?
I’m a Python guy! (Have used R a little)
07. Any frameworks/ libraries you use most in your experiments?
Since am more into deep learning and computer vision, I use PyTorch deep learning framework a lot. NumPy, Sci-kit learn, Pandas and all other ML related Python toolkits are in my toolbox always.
08. Machine learning is all about neural networks right?
No it’s not! This is one of the biggest myths! Artificial neural networks (ANNs) are only one family of algorithms which we can perform machine learning. There are plenty of other algorithms which are widely used in performing ML. Decision trees, Support Vector Machines, Naive Bayes are some popular ML algorithms which are not ANNs.
09. Why we need GPUs for training?
You need GPUs when you need to do parallel processing. The normal CPUs we have on our machines are typically having 4-5 cores and limited number of threads can be handled simultaneously. When it comes to a GPU, it’s having thousands of small cores which can handle thousands of computational threads in parallel. (For an example Nvidia 2080Ti is having 4352 CUDA cores in it). In Deep learning, we have to perform millions or calculations to train models. Running these workloads in GPUs is much faster and efficient.
10. When to use/ not to use Deep learning?
This is a tricky questions. Deep learning is always good in understanding the non-linear data. That’s why it’s performing really well in computer vision and natural language processing domains. If you have a such task, or your feature space is really large and having a massive amount of data, I’d suggest you to go with deep learning. If not sticking with traditional machine learning algorithms might be the best case.
11. Do I need to know all complex theories behind AI to develop intelligent applications?
Yes and No. In some cases, you may have to understand the theories behind AI/ML in order to develop a machine learning based applications. Mostly I would say model training and validation phases need this knowledge. Will say you are a software developer who’s very good with .Net/ Java and you are developing an application which is having a component where you have to read some text from a scanned document. You have to do it using computer vision. Fortunately you don’t have to build the component from the scratch. There are plenty of services which can be used as REST endpoints to complete the task. No need to worry on the underlying algorithms at all. Just use the JSON!
12. Should I build all my models from scratch?
This is a Yes/No answer too. This question comes mostly with deep learning model development. In some complex scenarios you may have to develop your models from the scratch. But most of the cases the problem you having can be defined as a object detection/ image classification/ Key phrase extraction from text etc. kinda problem. The best approach to go forward would be something like this.
Use a simple ANN and see your data loading and the related things are working fine.
Use a pre-trained model and see the performance (A widely used SOTA model would be the best choice).
If it’s not working out, do transfer learning and see the accuracy of the trained model. (You should get good results most of the times by this step)
Do some tweaks to the network and see if it’s working.
If none of these are working, then think of building a novel model.
13. Is cloud based machine learning is a good option?
In most of the industrial use cases yes! Since most of the data in prevailing systems are already sitting in the cloud and industries are heavily relying on cloud services these days, cloud based ML is a good approach. Obviously it comes with a price. When it comes to research phases, the price of purchiasing computation power maybe a problem. In those cases, my approach would be doing the research phase on-prem and moving the deployment to the cloud.
14. I’ve huge computer vision datasets to be trained? Shall I move all my stuff to the cloud?
Ehh… As I said previously, if you planning on a research project, which goes for a long time and need a lot of computational hours, I’d suggest to go with a local setup first, finalize the model and then move to the cloud. (If dollars aren’t your problem, no worries at all! Go for the cloud! Obviously it’s easy and more reliable)
15. Which cloud provider to choose?
There’s a lot of cloud providers out there having various services related to ML. Some provides out of the box services where you can just call and API to do the ML tasks (Microsoft Cognitive services etc. ). There are services where you can use your own data to train prevailing models (Custom Vision service by Azure etc.)
If you want end-to-end ML life cycle management, personally I find Azure ML service is a good solution since you can use any of your ML related frameworks and tools and just use cloud to train, manage and deploy the models. I find MLOps features that comes with Azure Machine Learning is pretty useful.
16. I’ve trained and deployed a pretty good machine learning model. I don’t need to touch that again right?
No way! You have to continuously check their performance and the accuracy they are providing for the newest data that comes to the service. The data that comes into the service may skewed. It’s always a good idea to train the model with more data. So better to have a re-training MLOps pipelines to iteratively check your models.
17. My DL models takes a lot of time to train. If I have more computation power the things will speed up?
mm.. Not all the time. I have seen cases where data loading is getting more time than model training. Make sure you are using the correct coding approaches and sufficient memory and process management. Make sure you are not using old libraries which may be the cause for slow processing times. If your code is clean and clear then try adjusting the computation power.
This is just few questions I noted down. If you have any other questions or concerns in the domain of machine learning/ deep learning and data science, just drop a comment below. Will try to add my thoughts there.
When it comes to real world data collections, we don’t have the prestige of having perfectly balanced labelled datasets for training models. Most of the machine learning algorithms are not immune for imbalanced classes and cause less accurate and biased models. There are many approaches that we can follow to tackle imbalanced data problem. Either we have to choose a ML algorithm which is reluctant for imbalanced data or we may have to generate synthetic data in order to make the classes balanced.
Neural networks are trained using backpropagation which treats each class same when calculating the loss. If the data is not balanced, that makes the model bias for one class than another.
A, B, C, D classes are imbalanced
I had to face this issue when experimenting with a computer vision based multi-class classification problem. The data I had was so much skewed and some classes had a very less amount of data compared to the majority class. Model was not performing well at all and need to take some actions to tackle the class imbalance problem.
These were the solutions I thought of try out.
Creating synthetic data – Creating new synthetic data points is one of the main methods which is used mostly for numerical data and in some cases in imagery data too with the help of GAN and image augmentations. As in the starting point, I took the decision not to go with synthetic data generation since it may introduce abnormal characteristics to my dataset. So I keep that for a later part.
Sampling the dataset with balanced classes – In this approach, what we normally do is, sample the dataset similar number of samples for each data label. For an example, will say we have a dataset which is having 3 classes named A, B & C with 100, 50, 20 data points for each class accordingly. When sampling what we do is randomly selecting 20 samples from each A, B & C classes and get a dataset with 60 data points.
In some cases this approach comes as a better option if we have very large amounts of data for each class (Even for the minority classes) In my case, I was not able to take the cost of loosing a huge portion of my data just by sampling it based on the data points having in the minority class.
Since both methods were not going well for me, I used a weighted loss function for training my neural network. Since this is a multi-class classification problem, I used Cross Entropy Loss in PyTorch as my loss function. (You can follow the similar approach if you using BCELoss for binary classification too)
import torch.nn as nn
#class weights for 6 class multi-class classification
class_weights = [0.5281, 0.8411, 0.9619, 0.8634, 0.8477, 0.9577]
#loss function with class weights
criterion = nn.CrossEntropyLoss(weight = class_weights)
How I calculated the weight for each class? –
This is so simple. What I did was calculating a manual re-scaling weight for each class and pass it to “weight” parameter in the loss function. Make sure that you have a Tensor with the size of number of classes as the class weights. (In simpler words each class should have a weight).
Hint : If you using GPU for model training, make sure to put your class weights tensor to the GPU too.
Did it worked? Hell yeah! I was able to train my model accurately with less bias and without overfitting for a single class by using this simple trick. Let me know any other trick you use for training neural network models with imbalanced data.
Docker has become the new norm of the software industry. Everyone is so obsessed with it since docker solves most of the issues software engineers and system administrators had with platform dependencies in application development and deployments.
“Docker is a tool that helps users to exploit operating-system-level virtualization to develop and deliver software in packages called containers.”
~ Wikipedia
Though the technical explanation sounds bit complicated, simply docker can be identified as a ‘VM like’ environment where you can build and deploy your software applications.
Why docker for machine learning/ deep learning?
We have endless discussions on how hard it is to configure the development and deployment environments in machine learning. Since python is the most used language for ML and DL experiments, dealing with python packages and making them all work seamlessly on your hardware can be a nightmare. Using cloud-based machine learning platforms or virtual machines are some of the options we can utilize to deal with this problem.
Being more flexible than virtual machines and easy migration capabilities, docker is one of the best ways for managing machine learning environments. Since docker has become the key component of MLOps it’s time for the data scientists for adapting docker in their developments.
Where and how we can use docker?
For me docker helps me out in 4 main stages in the machine learning experiment pipelines.
As a development environment.
I use to do lot of experiments in the domain of computer vision and deep learning. You may have experienced the pain of dealing libraries like opencv with python. So, I always use custom docker images with all the dependencies installed for running my experiments. This makes easy for me to collaborate with my peers easily without giving the hassle of replicating my development environment in their machines.
What about the huge amounts of data? Including those also inside the docker container? Nah. Always keeping the data in mounted volumes as well as the output files created from the experiments.
If you need GPU supported docker images, NVIDIA provides docker image variations that matches with your need on docker hub.
2.As a training environment.
You all know ML/ DL models normally take quite a big time for training. In my case, I use remote shared servers with GPUs for training my experiments. For that, the easiest way is containerizing the experiment and pushing to the server.
3. As a deployment environment.
Another popular use case of docker is in the deployment phase. Normally the deployment environment should fulfil required dependencies in order to inference the ML/DL model seamlessly. Since a docker container can be shipped across platforms easily without worrying about hardware level dependencies, it’s really easy to use docker for deploying ML models.
4. Docker for cloud-based machine learning
Most of the data scientists are using cloud-based machine learning platforms like Azure machine learning today with their flexibility and resources. Containerized experiments are the main component these services use in order to run them on cloud. When it comes to Azure ML you can use their default docker image for experiments or you can specify your custom base image for model development and training.
Take a look on this documentation for deploy Azure ML models using a custom docker base image.
So, docker has become a life saver for me since it reduces a lot of headache occurring with machine learning model life-cycle. Will come up with a sample experiment on using docker for training a machine learning model in the next post.