
Happy 2022!
It’s almost 7 years since I started playing with machine learning and related domains. These are some FAQs that comes for me from peers. Just added my thoughts on those. Feel free to any questions or concerns you have on the domain. I’ll try my best to add my thoughts on that. Note that all these answers are my personal opinions and experiences.
01. How to learn the theories behind machine learning?
The first thing I’d suggest would be ‘self-learning’. There are plenty of online resources out there where you can start studying by your own. Most of them are free. Some may need a payment for the certification (That’s totally up to you to pay and get it). I’ve listed down some of the famous places to get a kickstart for learning AI. Just take a look here.
Next would be keep practising. Never stop coding and training models in various domains. Kaggle is a good place to sharpen your skill set. Keep learning and keep practising at the same time.
02. Do we really need mathematics for ML?
Yes. To some extend you should know the theories behind probability and and some from basic mathematics. No need to worry a lot on that. As I said previously, there are plenty of places to catch up your maths too.
03. Is there a difference between data analysis and machine learning?
Yes. There is. Data analysis is about find pattern in the prevailing data and obtain inferences due to those patterns. It may have the data visualization components too. When is comes to machine learning, you train a system to learn those patterns and try to predict the upcoming pattern.
04. Does the trend in AI/ML going to fade out in the near future?
Mmm.. I don’t think so. Can’t exactly say AI is going to be ‘the’ future. Since all these technical advancements going to generate hell a lot of data, there should be a way to understand the patterns of those data and get a value out of that. So, data science and machine learning is going to be the approach to go for.
Right… those are some general questions I frequently get from people. Let’s move into some technicalities.
05. What’s the OS you use on your work rig?
Ubuntu! Yes it’s FOSS and super easy to setup all the dependencies which I need on it. (I did a complete walk through on my setup previously. Here’s it). Sometimes I use Windows too. But if it’s with docker and all, yes.. Ubuntu is the choice I’m going with.
06. What’s your preferred programming language to perform machine learning experiments?
I’m a Python guy! (Have used R a little)
07. Any frameworks/ libraries you use most in your experiments?
Since am more into deep learning and computer vision, I use PyTorch deep learning framework a lot. NumPy, Sci-kit learn, Pandas and all other ML related Python toolkits are in my toolbox always.
08. Machine learning is all about neural networks right?
No it’s not! This is one of the biggest myths! Artificial neural networks (ANNs) are only one family of algorithms which we can perform machine learning. There are plenty of other algorithms which are widely used in performing ML. Decision trees, Support Vector Machines, Naive Bayes are some popular ML algorithms which are not ANNs.
09. Why we need GPUs for training?
You need GPUs when you need to do parallel processing. The normal CPUs we have on our machines are typically having 4-5 cores and limited number of threads can be handled simultaneously. When it comes to a GPU, it’s having thousands of small cores which can handle thousands of computational threads in parallel. (For an example Nvidia 2080Ti is having 4352 CUDA cores in it). In Deep learning, we have to perform millions or calculations to train models. Running these workloads in GPUs is much faster and efficient.
10. When to use/ not to use Deep learning?
This is a tricky questions. Deep learning is always good in understanding the non-linear data. That’s why it’s performing really well in computer vision and natural language processing domains. If you have a such task, or your feature space is really large and having a massive amount of data, I’d suggest you to go with deep learning. If not sticking with traditional machine learning algorithms might be the best case.
11. Do I need to know all complex theories behind AI to develop intelligent applications?
Yes and No. In some cases, you may have to understand the theories behind AI/ML in order to develop a machine learning based applications. Mostly I would say model training and validation phases need this knowledge. Will say you are a software developer who’s very good with .Net/ Java and you are developing an application which is having a component where you have to read some text from a scanned document. You have to do it using computer vision. Fortunately you don’t have to build the component from the scratch. There are plenty of services which can be used as REST endpoints to complete the task. No need to worry on the underlying algorithms at all. Just use the JSON!
12. Should I build all my models from scratch?
This is a Yes/No answer too. This question comes mostly with deep learning model development. In some complex scenarios you may have to develop your models from the scratch. But most of the cases the problem you having can be defined as a object detection/ image classification/ Key phrase extraction from text etc. kinda problem. The best approach to go forward would be something like this.
- Use a simple ANN and see your data loading and the related things are working fine.
- Use a pre-trained model and see the performance (A widely used SOTA model would be the best choice).
- If it’s not working out, do transfer learning and see the accuracy of the trained model. (You should get good results most of the times by this step)
- Do some tweaks to the network and see if it’s working.
- If none of these are working, then think of building a novel model.
13. Is cloud based machine learning is a good option?
In most of the industrial use cases yes! Since most of the data in prevailing systems are already sitting in the cloud and industries are heavily relying on cloud services these days, cloud based ML is a good approach. Obviously it comes with a price. When it comes to research phases, the price of purchiasing computation power maybe a problem. In those cases, my approach would be doing the research phase on-prem and moving the deployment to the cloud.
14. I’ve huge computer vision datasets to be trained? Shall I move all my stuff to the cloud?
Ehh… As I said previously, if you planning on a research project, which goes for a long time and need a lot of computational hours, I’d suggest to go with a local setup first, finalize the model and then move to the cloud. (If dollars aren’t your problem, no worries at all! Go for the cloud! Obviously it’s easy and more reliable)
15. Which cloud provider to choose?
There’s a lot of cloud providers out there having various services related to ML. Some provides out of the box services where you can just call and API to do the ML tasks (Microsoft Cognitive services etc. ). There are services where you can use your own data to train prevailing models (Custom Vision service by Azure etc.)
If you want end-to-end ML life cycle management, personally I find Azure ML service is a good solution since you can use any of your ML related frameworks and tools and just use cloud to train, manage and deploy the models. I find MLOps features that comes with Azure Machine Learning is pretty useful.
16. I’ve trained and deployed a pretty good machine learning model. I don’t need to touch that again right?
No way! You have to continuously check their performance and the accuracy they are providing for the newest data that comes to the service. The data that comes into the service may skewed. It’s always a good idea to train the model with more data. So better to have a re-training MLOps pipelines to iteratively check your models.
17. My DL models takes a lot of time to train. If I have more computation power the things will speed up?
mm.. Not all the time. I have seen cases where data loading is getting more time than model training. Make sure you are using the correct coding approaches and sufficient memory and process management. Make sure you are not using old libraries which may be the cause for slow processing times. If your code is clean and clear then try adjusting the computation power.
This is just few questions I noted down. If you have any other questions or concerns in the domain of machine learning/ deep learning and data science, just drop a comment below. Will try to add my thoughts there.




 We discussed the possibility of transferring the knowledge learned by a ConvNet to another. If you new to the idea of transfer learning, please go check up the
We discussed the possibility of transferring the knowledge learned by a ConvNet to another. If you new to the idea of transfer learning, please go check up the  So, this is going to be an image classification task. We going to take the advantage of ImageNet; and the state-of-the-art architectures pre-trained on ImageNet dataset. Instead of random initialization, we initialize the network with a pretrained network and the convNet is finetuned with the training set.
So, this is going to be an image classification task. We going to take the advantage of ImageNet; and the state-of-the-art architectures pre-trained on ImageNet dataset. Instead of random initialization, we initialize the network with a pretrained network and the convNet is finetuned with the training set.


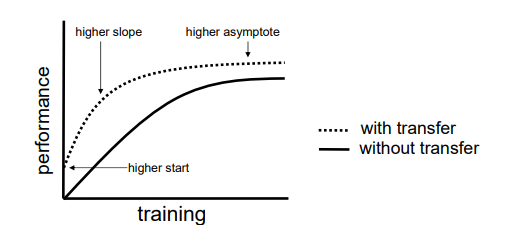
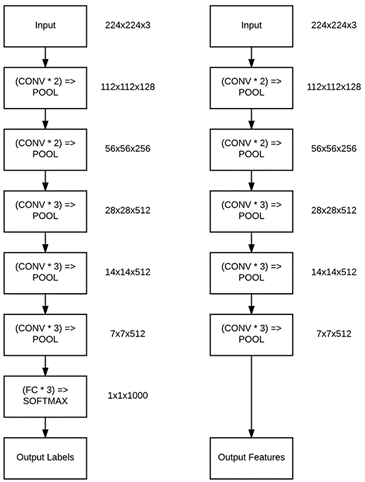
 Let’s discuss how to perform transfer learning with an example in the next post. 😊
Let’s discuss how to perform transfer learning with an example in the next post. 😊
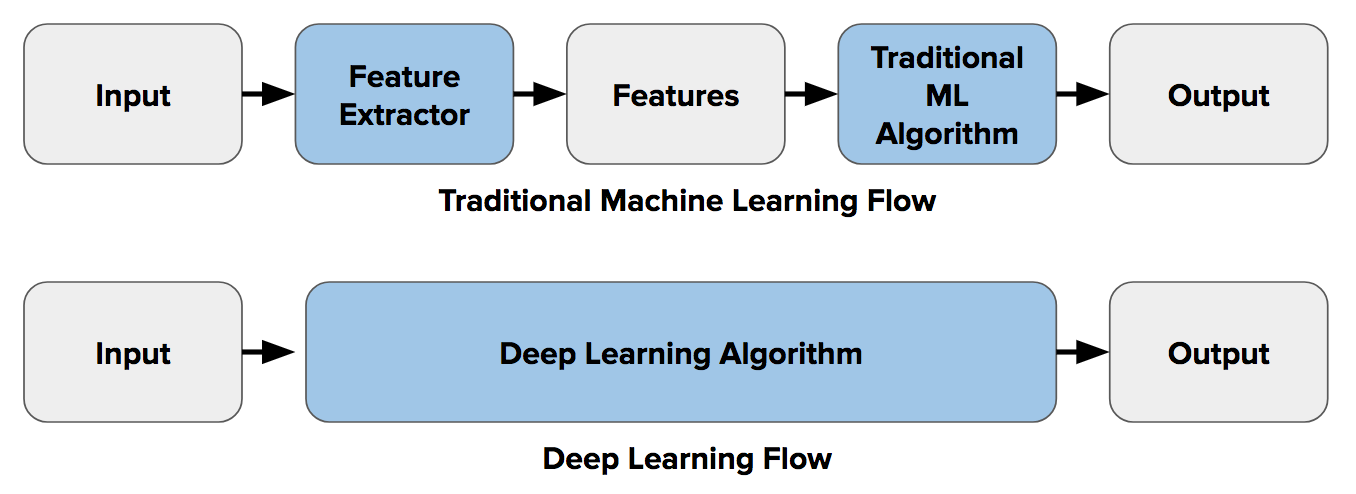 The boom started with the convolutional neural networks and the modified architectures of ConvNets. By now it is said that some convNet architectures are so close to 100% accuracy of image classification challenges, sometimes beating the human eye!
The boom started with the convolutional neural networks and the modified architectures of ConvNets. By now it is said that some convNet architectures are so close to 100% accuracy of image classification challenges, sometimes beating the human eye!